1 前言
1.1 本章概要
-
逻辑回归模型是用下面分布表示的模型,用于分类
其中 $k = 1, 2, …, K-1$
逻辑回归模型是用输入的线性函数表示输出的对数几率模型
-
最大熵模型是用下面分布表示的分类模型
- $Z_w(x)$ 是归一化因子
- $f_i$ 是特征函数
- $w_i$ 特征权值
-
最大熵原理认为在所有可能的概率模型(分布)的集合中,熵最大的模型是最好的模型
-
最大熵原理应用到分类模型学习中,有以下约束最优化问题:
约束条件:
求解此优化问题的对偶问题得到最大熵模型
-
逻辑回归模型和最大熵模型都是对数线性模型
-
逻辑回归模型和最大熵模型一般用极大似然估计,或正则化的极大似然估计
-
求解最优化问题的算法有迭代尺度法、梯度下降法、拟牛顿法
1.2 目录
- 逻辑回归模型
1.1 逻辑分布
1.2 二项逻辑回归模型
1.3 模型参数估计
1.4 多项逻辑回归 - 最大熵模型
2.1 最大熵原理
2.2 最大熵模型的定义
2.3 最大熵模型的学习
2.4 极大似然估计 - 模型学习的最优化算法
3.1 改进的迭代尺度法
3.2 拟牛顿法
2 读书笔记
2.1 逻辑回归模型
2.1.1 逻辑分布
设 $X$ 是连续随机变量, $X$ 服从逻辑分布是指 $X$ 具有以下分布函数和密度函数:
式中, $\mu$ 为位置参数,$\gamma > 0$ 为形状参数
逻辑分布的密度函数和分布函数如下:

2.1.2 二项逻辑回归模型
二项逻辑回归模型是如下的条件概率分布:
对于新的输入 $x$,求出 $P(Y = 1 \mid x)$ 和 $P(Y = 0 \mid x)$,求实例 $x$ 分配到概率值大的一类
几率
事件发生的概率与不发生概率的比值 $\dfrac{p}{1-p}$
对数几率或 logit 函数是:
对数几率的线性模型表示为:
由此可求出逻辑回归模型:
2.1.3 模型的参数估计
极大似然估计法估计参数,对于 0-1 分布的样本,有
对应的似然函数为:
再求对数似然函数的极大值(梯度下降或拟牛顿法),可得 w 的估计值
当求出 w 的极大似然估计值 $\hat{w}$ 后,逻辑回归模型为:
2.1.4 多项逻辑回归模型
模型为:
2.2 最大熵模型
则最大熵原理推导
2.2.1 最大熵原理
最大熵原理认为在所有可能的概率模型(分布)的集合中,熵最大的模型是最好的模型。约束条件确定概率模型的集合
2.2.2 最大熵模型的定义
假设满足所有的约束条件的模型集合为:
定义在条件概率分布 $P(Y \mid X)$ 上的条件熵为:
则模型集合 $M$ 中条件熵 $H(P)$ 最大的模型成为 最大熵模型
2.2.3 最大熵模型的学习
最大熵模型的学习过程就是模型的求最优解过程。所以学习过程可以转化成约束最优化过程
对于训练集 $T = {(x_1, y_1), (x_2, y_2), …, (x_N, y_N) } $ 以及特征函数 $ f_i(x, y)$,最大熵模型的学习等价于约束最优化问题:
约束条件:
按惯例转化为求最小值问题:
约束条件:
上面式子的解就是最大熵模型学习的解,其解为:
这里:
$L$ 是拉格朗日函数:
3 导读笔记
3.1 逻辑回归模型
对数线性模型的形式为: $logP(y \mid x) = w \cdot x$
对于给定的 $x$,我们希望把它的类别概率表示为 $P(y = 1 \mid x) = \pi(x)$,其中 $\pi(x) \in [0, 1]$
为了用线性函数 $w \cdot x$ 来表示 $\pi(x)$ 的特征,需要一个变换,把 $(-\infty, +\infty) \to [0, 1]$,用到了 logit 变换:
反解出逻辑回归模型:
只需要求出 $w$ 就有了模型,然后对于新的 $x$,求出对应的 $P(Y=1 \mid x)$,当 $P(Y=1 \mid x) > 0.5$ 时,判定分类为 1
求解 w
用极大似然估计法求解 $w$:给定 w,求样本的联合概率密度,让它最大,即可求出 w
对于 $y_i \in {0, 1}$,给定 $\pi(x)$ 后,$y$ 的概率分布为:
对于 N 个样本的极大似然估计函数 $L(w)$:
只要求 $\max logL(w)$ 的 $w$ 即可。一般用梯度下降法,给定一个初值 $w_0$ 即可找到 $w*$
3.2 最大熵模型
原理:在满足约束条件的模型集合中,选择熵最大的模型(混乱程度最大的模型)。因为在条件不足时,只能假设各种情况出现的概率相同
例如:对于 $X \in {A, B, C, D, E}$,估计各值出现的概率。
约束条件:
在满足约束的模型中找最乱的,所以各概率相同,所以有 $P(x_i) = 1/5$
对于新的约束条件:
如何找集合中熵最大的模型
因为熵 $H(p) = - \sum p_i log p_i,\max H = \min [-H]$,所以:
要求的模型等价于求最优问题:
约束条件:
我们 $x$ 是已知的,如何把已知的 $x$ 信息加入来求 $p(y)$?
用条件熵:
因为熵 $H(p) = -\sum p_i \log p_i$
所以:
我们希望总体 $x$ 的分布用样本上的 $x$ 分布(也称经验分布)来代替,即
就要引入约束条件:
上式的 $p(x, y)$ 为联合概率分布,上式的含义是让每个特征在总体中出现的概率 = 样本中出现的概率
其中 $f_i(x, y)$ 是特征函数,代表观察到的信息
这样最大熵模型对应的最优化问题如下:
约束条件 n+1 个:
其中:$i = 1, 2, …, n$
最优问题的求解结果为:
其中:
求解的流程:
- 给定一个 $x$,求 $y$ 取不同值时对应的概率分布
- $(x, y)$ 满足 n 个 $f_i$ 的要求,$w_i$ 是特征 $f_i$ 的重要程度,当满足的特征越多且特征越重要,$P_w$ 值越大
- 求 $w$,代入 $P_w(y \mid x)$ 就得到模型
3.2 拉格朗日对偶性
对于任意的优化问题,有一个优化的目标函数,记为 $f$,需要优化的变量记为 $x$,约束最优化问题一般形式为:
约束条件:
$c_i$ 称为不等式约束,$h$ 称为等式约束
以上的原始问题记为 $P$,它对应一个拉格朗日函数:
其中:$\alpha$ 称为不等式约束因子,$\beta$ 称为等式约束因子,$\alpha_i$ 对应第 $i$ 个不等式约束,$\alpha_i \ge 0$,$\beta_j$ 不作要求。
满足约束条件的 $x$ 的范围称为可行域,即把 $k+l$ 个集合求交集。
优化问题就是在可行域中,找到 $x$ 使 $f$ 最小,对应的结果就是 $x, P$,用数学表达式写作:
也就是满足尽可能多的约束下,让 $f$ 取到最小值
- 当 $c_i, h_j$ 无约束时,总可以让后面的部分为 $\infty$
- 当 $c_i(x) \le 0, h_j(x) = 0$ 时,$L$ 要最大,第 3 项为 0 第 2 项小于 0,所以最大为 $f(x)$
因此,原始问题等价于极小极大化 $L$ 函数,所以原始问题的对偶性问题可以写成:
首先求无约束问题,再求有约束最优问题
因此,拉格朗日对偶问题为:
约束条件 $\alpha_i \ge 0$,最优解:$\alpha^, \beta^$,最优值 $d^*$
下面再看 $P^$ 和 $d^$ 的关系
对偶问题的最优值给原始问题的最优值提供了下界,$P^* \ge d^*$
什么时候 $P^* = d^*$ ? 当原始问题满足:
4 总结
4.1 什么是梯度下降?
-
梯度方向是函数增长最快的方向,负梯度是函数减小最快的方向
-
要求函数的最小值,可以从任意点 $X_0 = (x_1, x_2, …, x_n)$ 开始进行一个迭代过程
一直到收敛条件满足
4.2 什么是 Logistic 回归?
可以想成对数几率【拟合】,就是用线性函数 wx 去拟合对数几率
-
为什么是对数几率?
因为
$ wx = \log \frac{p}{1-p} > log 1 = 0$
所以当 $wx > 0$ 是可以知道 $\dfrac{p}{1-p} > 1$,就说明样本 $x$ 是正样本
-
为什么 wx > 0 时,x 是正样本?
因为 $wx = \log \dfrac{p}{1-p}$,这里 $p = p(Y=1 \mid x)$
那么当 $p>0.5$ 时,$\dfrac{p}{1-p}>1$ , $\log \dfrac{p}{1-p} > 0$
-
什么是 Logistic 回归模型?
Logistic 回归是统计学习中的分类方法
-
统计学习
计算机基于数据构建概率统计模型,并用模型对数据进行预测与分析的学科
-
统计学习的方法
在假设数据集是独立同分布产生的前提下,应用某个评价标准,从假设空间中根据最优算法选择一个最优的模型。统计学习方法的三要素:模型的假设空间、模型选择的标准、模型学习的算法
Logistic 回归模型是利用 Logistic 回归方法得到的一个线性分类模型,这个线性模型的假设空间是线性空间 wx,这个线性模型的评价准则是极大似然估计,这个线性模型的最优算法是用梯度下降法
假设空间是输入空间到输出空间的映射的集合
-
-
Logistic 回归的由来:
希望通过 wx 直接预测 x 属于正样本的概率。但 wx 值域无界,所以用 sigmoid 函数把 wx 映射到[0, 1],所以有 $p(Y=1 \mid x) = sigmoid(x)$
-
极大似然估计
对参数的求解采用了极大似然估计,由数据集的分布
可以将分布统一写成:
那么对于训练样本 $D = {(x_1, y_1), (x_2, y_2), …, (x_n, y_n)}$,有极大似然函数:
其中:
所以它的对数似然估计就是:
那么现在要求最大似然估计值,等价于求如下最小问题:
这个就是学习方法的评价标准
-
梯度下降法
这是最优算法,寻找最优模型。目标函数的梯度为:
得到梯度后,w 的更新公式:
5 代码实践
5.1 生成数据
从testSet.txt中读取测试数据
def load_dataset():
with open('testSet.txt') as fr:
data_list = [line.strip().split('\t') for line in fr.readlines()]
dataset = [[1.0, float(d[0]), float(d[1])] for d in data_list]
labels = [int(d[2]) for d in data_list]
return data_list, np.array(dataset), np.array(labels)
5.2 绘制数据
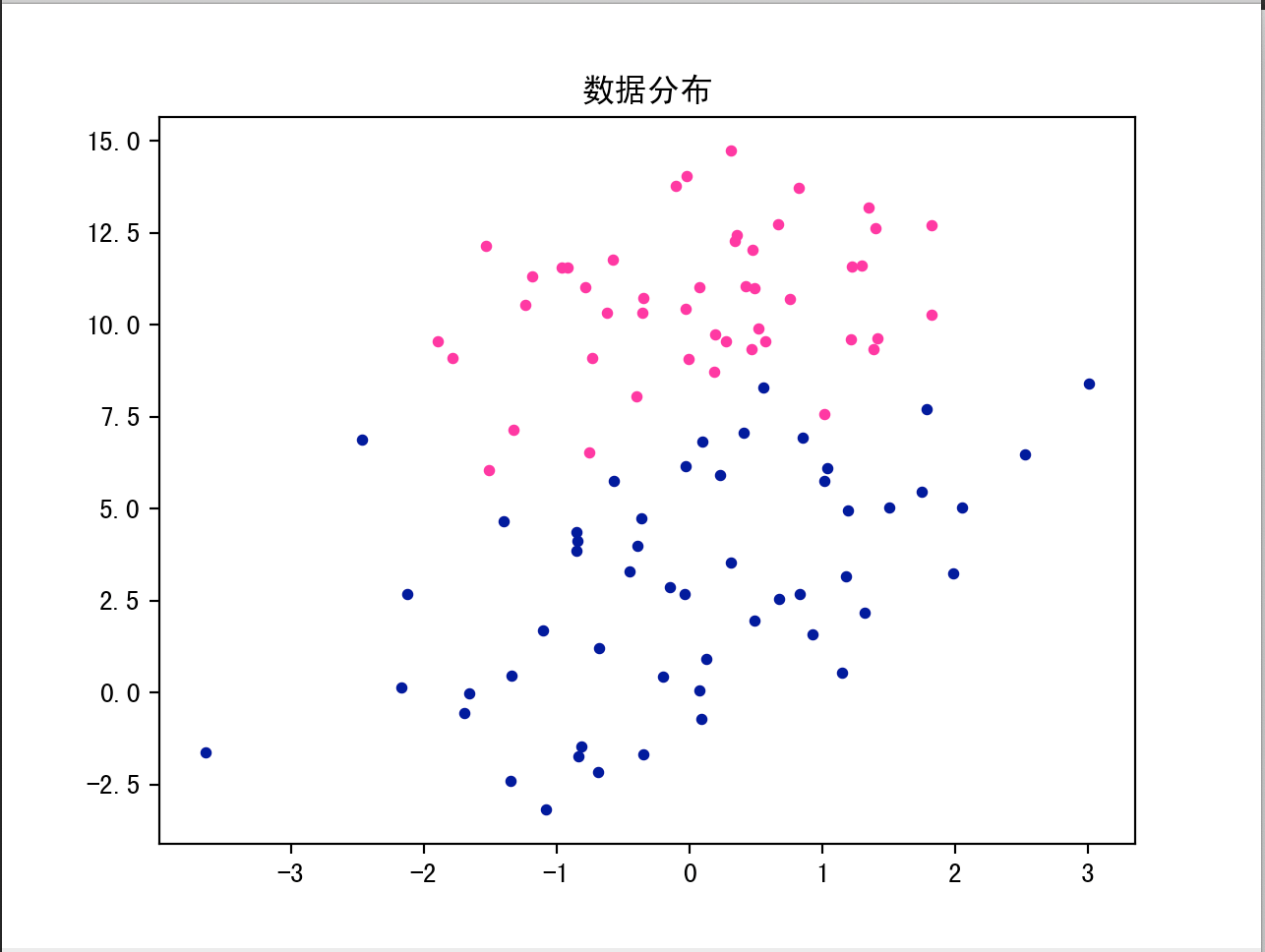
def plot_dataset(data_list):
x1 = [float(d[0]) for d in data_list if d[2] == '0']
y1 = [float(d[1]) for d in data_list if d[2] == '0']
x2 = [float(d[0]) for d in data_list if d[2] == '1']
y2 = [float(d[1]) for d in data_list if d[2] == '1']
fig = plt.figure()
plt.title("数据分布")
plt.scatter(x1, y1, c='deeppink', s=10)
plt.scatter(x2, y2, c='darkblue', s=10)
# plt.show()
5.2.1 scatter 函数
matplotlib.pyplot.scatter(x, y, s=None, c=None,
marker=None, cmap=None, norm=None,
vmin=None, vmax=None, alpha=None,
linewidths=None, verts=None, edgecolors=None,
hold=None, data=None, **kwargs)
常用参数说明:
| 参数 | 类型 | 说明 | 默认值 |
|---|---|---|---|
| x,y | array | 表示 x 轴与 y 轴对应的数据; | 无 |
| s | 数值或一维的array | 表示散点图中点的大小,若是一维数组,则表示散点图中每个点的大小; | None |
| c | 颜色或一维的array | 表示散点图中点的颜色,若是一维数组,则表示散点图中每个点的颜色; | None |
| marker | string | 表示散点的类型; | o |
| alpha | 0~1之间的小数 | 表示散点的透明度; | None |
-
x/y:数据
都是向量,而且必须长度相等
-
s:标记大小
以平方磅为单位的标记面积,指定为下列形式之一:
-
数值标量: 以相同的大小绘制所有标记
-
行或列向量: 使每个标记具有不同的大小。x、y 和 sz 中的相应元素确定每个标记的位置和面积。sz 的长度必须等于 x 和 y 的长度。
-
[]: 使用 36 平方磅的默认面积。
-
-
C:标记颜色
标记颜色,指定为下列形式之一:
-
RGB 三元数或颜色名称 - 使用相同的颜色绘制所有标记。
-
由 RGB 三元数组成的三列矩阵 - 对每个标记使用不同的颜色。矩阵的每行为对应标记指定一种 RGB 三元数颜色。行数必须等于 x 和 y 的长度。
-
向量 - 对每个标记使用不同的颜色,并以线性方式将 c 中的值映射到当前颜色图中的颜色。c 的长度必须等于 x 和 y 的长度。要更改坐标区的颜色图,请使用 colormap 函数。
如果散点图中有三个点,并且您希望这些颜色成为颜色图的索引,请以三元素列向量的形式指定 c。
选项 说明 对应的 RGB 三元数 ‘red’ 或 ‘r’ 红色 [1 0 0] ‘green’ 或 ‘g’ 绿色 [0 1 0] ‘blue’ 或 ‘b’ 蓝色 [0 0 1] ‘yellow’ 或 ‘y’ 黄色 [1 1 0] ‘magenta’ 或 ‘m’ 品红色 [1 0 1 ] ‘cyan’ 或 ‘c’ 青蓝色 [0 1 1] ‘white’ 或 ‘w’ 白色 [1 1 1] ‘black’ 或 ‘k’ 黑色 [0 0 0] -
-
marker: 标记样式
值 说明 ‘o’ 圆圈 ’+’ 加号 ’*’ 星号 ’.’ 点 ‘x’ 叉号 ‘square’ 或 ‘s’ 方形 ‘diamond’ 或 ‘d’ 菱形 ’^’ 上三角 ‘v’ 下三角 ’>’ 右三角 ’<’ 左三角 ‘pentagram’ 或 ‘p’ 五角星(五角形) ‘hexagram’ 或 ‘h’ 六角星(六角形) ‘none’ 无标记 -
edgecolors:轮廓颜色
如果无,则默认为’face’。如果’face’,边缘颜色将永远是相同的。如果它是’none’,补丁边界不会被画下来。
-
alpha:透明度
[0,1]:1不透明,0透明
-
cmap:色彩盘
可以使用默认的也可以使用自定义的,它实际上就是一个 三列的矩阵(或者说,shape 为 [N, 3]的 array )
-
矩阵中的值 取值范围 为 [0. , 1.]
-
每一行代表一个颜色 (RGB)
-
-
linewidths:线宽
标记边缘的宽度,默认是’face’
-
注意事项:
color、marker等不能同时作为一个参数,plt.scatter(x1, y1, ‘bo’, s=5)不合法。
5.2.2 基本用法
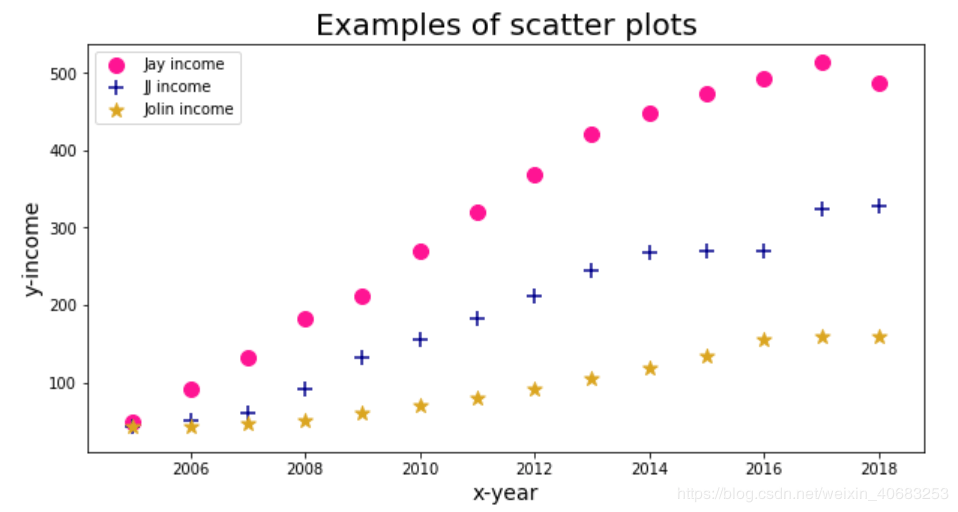
import pandas as pd
import matplotlib.pyplot as plt
datafile = u'D:\\pythondata\\learn\\matplotlib.xlsx'
data = pd.read_excel(datafile)
plt.figure(figsize=(10,5))#设置画布的尺寸
plt.title('Examples of scatter plots',fontsize=20)#标题,并设定字号大小
plt.xlabel(u'x-year',fontsize=14)#设置x轴,并设定字号大小
plt.ylabel(u'y-income',fontsize=14)#设置y轴,并设定字号大小
plt.scatter(data['时间'],data['收入_Jay'], s=100, c='deeppink', marker='o')
plt.scatter(data['时间'],data['收入_JJ'], s=100, c='darkblue', marker='+')
plt.scatter(data['时间'],data['收入_Jolin'], s=100, c='goldenrod', marker='*')
plt.legend(['Jay income', 'JJ income', 'Jolin income'])#标签
plt.show()#显示图像
5.3 Logistic 回归分类
5.3.1 理论推导过程
即 Logistic 拟合,也就是用 $wx$ 拟合对数几率值,用数学式表示为:$ w \cdot x = \log \dfrac{p}{1-p}$
于是反解出 Logistic 回归模型:
只要求出 $w$ 就有了模型,然后对于新的 $x$,求出对应的 $P(Y=1 \mid x)$,当 $P(Y=1 \mid x) > 0.5$ 时,判定分类为 1
要求出 $w$ ,我们引入了似然函数 $L(w \mid X)$,并使用极大似然估计准则选出 Logistic 回归模型的参数
-
似然函数:
-
对数似然函数:
-
最大似然估计准则:
-
梯度下降
5.3.2 估计模型参数
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
def pred(x, w):
logit = sigmoid(w, x)
return 1 if logit > 0.5 else 0
def grad_descent(x, labels, alpha, max_iter):
w = np.random.randn(len(x[0]))
for i in range(max_iter):
pred = sigmoid(x.dot(w))
loss = pred - labels # 公式求出
grad = loss.T.dot(x)
w = w - alpha * grad
return w
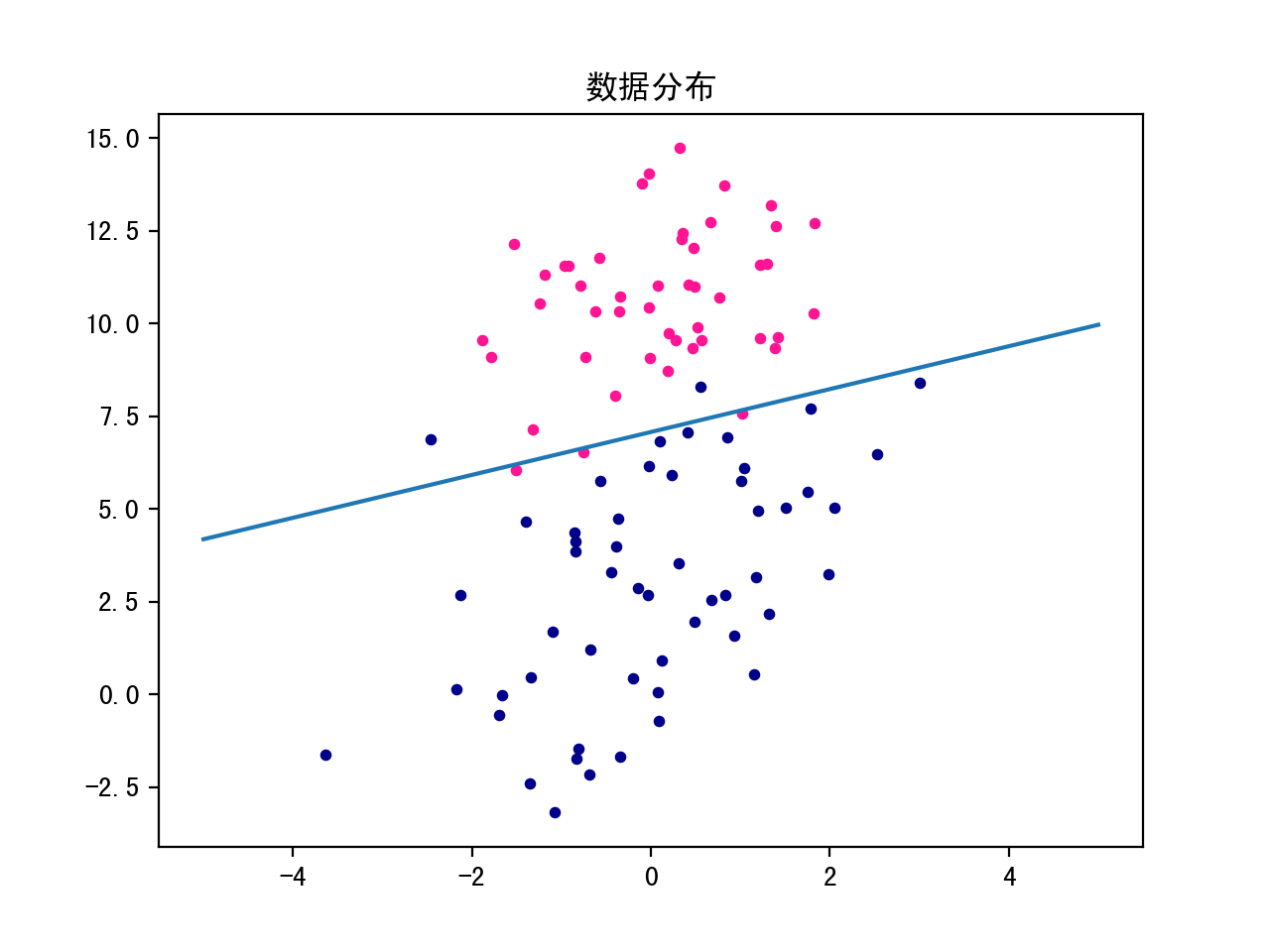
def plot_line(w):
x = np.linspace(-5, 5, 100)
y = (w[0] + w[1] * x) / (-w[2])
plt.plot(x, y)
plt.show()
if __name__ == "__main__":
data_list, dataset, labels = load_dataset()
plot_dataset(data_list)
w = grad_descent(dataset, labels, 0.1, 1000)
plot_line(w)
5.3.2 预测新数据所属类别
test_cls = pred(x, w)
6 补充
6.1 什么是似然
似然是似然函数的简称
-
定义
设总体 X 服从分布 $P(x;θ)$(当X是连续型随机变量时为概率密度,当X为离散型随机变量时为概率分布),θ为待估参数,$X_1,X_2,…X_n$ 是来自于总体 X 的样本,$x_1,x_2…x_n$ 为样本 $X_1,X_2,…X_n$ 的一个观察值,则样本的联合分布(当X是连续型随机变量时为概率密度,当X为离散型随机变量时为概率分布) $L(θ) = P(x_1,x_2,…,x_n;θ)= \prod P(x_i;θ) $ 称为似然函数,其中θ是一个列向量
-
百度
似然是对 likelihood 的翻译,即“可能性”
-
其他
-
在频率推论中,似然函数(简称似然)是一个在给定了数据的情况下,关于模型参数的函数
-
在数理统计中,概率描述的是一个事件发生的可能性;似然描述的是给定了结果之后,模型参数为某个值的可能性。
-
$p(x \mid \theta)$ 是有着两个变量的函数,将 $\theta$ 设为常数就得到一个概率函数(关于 x 的函数);将 x 设为常数,就得到似然函数(关于 $\theta$ 的函数)$L( \theta \mid x)$。当结果与参数相对应时,似然与概率在数值上是相等的
-
$p(x \mid \theta)$ 如果 $\theta$ 已知,则是概率函数,它描述的是对于不同的 x,出现的概率是多少;如果 $x$ 已知,$\theta$ 未知,则是似然函数,它描述的是在相同 x 下,所属不同 $\theta$ 的概率
-
概率和似然的区别:
-
概率,是在已知概率分布参数的情况下,预测结果;
-
似然则是用于在已知结果时,对结果所属的概率分布的参数的估计
-
-
假设观察到 N 个数据 $X = {x_1, x_2, …, x_N}$,我们假设这些数据来源于正太分布,设定概率密度函数为 $f(x; \mu, \delta)$,那么这组~数据~在假设的概率分布中~出现的可能性~就是它们概率的乘积:$P(X \mid \mu, \delta) = \prod\limits_{i=1}^N P(x_i \mid \mu, \delta) = L(\mu, \delta \mid X) $,这里我们叫 $L(\mu, \delta \mid X)$ 为似然函数,含义是已知样本 $X$ 时,参数 $\mu, \delta$ 为各种值的可能性
-
-
总结
-
似然也称似然函数,是给定样本 $X$ 后,模型参数取某个值的概率
-
似然函数写作:$ L(\theta \mid X)$
-