1 硬间隔最大化的线性支持向量机
支持向量机是一种分类模型,它可以在线性可分的数据中找到一个超平面,把数据分成两类。在超平面一侧的数据为正类,另一侧的为负类。
那么,我们拿到数据集 $D = {(x_1, y_1), (x_2, y_2), …, (x_n, y_n)}$,怎么找超平面呢?
首先,我们定义超平面的方程为 $w^T \cdot x + b = 0$,简写成 $(w, b)$ 。那么,数据集中的样本 $(x_i, y_i)$ 到这个平面的距离可以表示成: $\dfrac{y_i(w^T \cdot x_i + b)}{\parallel w \parallel}$ 。支持向量机的思想是让支持向量到超平面的距离尽可能大,而支持向量就是到超平面距离最小的样本点,即 $\mathop{\arg\min}\limits_{i} \dfrac{y_i(w^T \cdot x_i + b)}{\parallel w \parallel}$ 得到的各个样本 $(x_i, y_i)$。然后再选取超平面 $(w, b)$ 让这个距离最大,即:
求出上面的 $(w, b)$ 就是我们需要的超平面。
下面就是求解的过程。
我们知道, $y_i(w^T \cdot x_i + b) \ge 1$ 而且只有支持向量才能取到 1,所以我们把上式写成:
这就是 SVM 学习的最优化问题。整理一下就是:
对于一个训练数据集 $D = {(x_1, y_1), (x_2, y_2), …, (x_n, y_n)}$,要得到最大分隔超平面和分类决策函数。
就是要求最优化问题:
约束条件:
求出后得到最大分隔超平面:
分类决策函数:
下面我们来看一个实际例子:
对于一个训练数据集,其正样本点是 $x_1 = (3, 3)^T, x_2 = (4, 3)^{T}$ ,负样本点是 $x_3 = (1, 1)^{T}$ ,如何找到最大间隔分离超平面?
因为最大分隔距离跟 $\dfrac{1}{\parallel w \parallel}$ 有关,所以倒过来最大变成最小,得到 $\mathop{\arg\min}\limits_{(w, b)} \dfrac{1}{2} \parallel w \parallel ^2$
对于本题:
约束条件为:$y_i(w^T \cdot x_i + b) \ge 1$,所以:
在约束条件下就出最优化问题的解:$w_1 = w_2 = \dfrac{1}{2}, b = -2$ ,所以分隔超平面为:
其中,$x_1 = (3, 3)^T, x_3 = (1, 1)^T$ 为支持向量
1.1 对偶算法
SVM 最优化问题:
约束条件:
这个 SVM 最优化问题的求解,要先确定约束条件的范围,然后在范围中找最值,这个过程比较复杂。我们希望通过一个式子把最值和约束条件都包含进来,这就是拉格朗日函数法。我们引入拉格朗日乘子 $\alpha_i \ge 0, i = 1, 2, …, N$ 构造拉格朗日函数:
再有拉格朗日对偶性原理,原始问题的对偶问题是极大极小问题:
对于 $\mathop{\arg\min}\limits_{(w, b)}$ 的部分,只要求 $\dfrac{\partial L}{\partial w}$ 和 $\dfrac{\partial L}{\partial b}$ 就可以了,于是有:
这样求出 $w^* = \sum\limits_{i=1}^{N} \alpha_i y_i x_i$, 在带入 $L(w, b, \alpha)$ 就可以得到:
又因为 $b \cdot \sum\limits_{i=1}^{N} \alpha_iy_i = b\cdot 0 = 0$ ,所以:
那么原始问题的对偶问题就是:
加上负号,最大变最小:
约束条件:
上面就是对偶最优化问题。
当我们求出最优解 $\alpha^{\ast} = (\alpha_1^{\ast}, \alpha_2^{\ast}, \dots, \alpha_N^{\ast})$ 后,可以计算:
再选出其中的一个正分量 $\alpha_{j}^{\ast} > 0$,计算:
因为对此 $j$ 有:
把 $w^*$ 代入,并且有 $y_j^2 = 1$,所以结果如 $\eqref{1.11}$ 所示
1.2 总结
对于给定的训练数据集,可以先求出对偶问题的 $\alpha^{\ast}$,再求 $(w^{\ast}, b^{\ast})$,从而得到分隔超平面以及分类决策函数。这种算法称为支持向量机的对偶学习算法
2 软间隔最大化的线性支持向量机
上面的支持向量机学习算法只针对于线性可分数据,对于线性不可分的数据,因为上面的约束条件不成立,所以不适用。
这里的线性不可分数据应该解释为:数据中存在少许特异样本点,除去这些外的数据集是线性可分的。
线性不可分意味着对于特异样本点 $(x_i, y_i)$ 它不满足 $y_i(w^T \cdot x_i + b) \ge 1$。我们可以让它加上一个松弛变量 $\xi_i$,使 $y_i(w^T \cdot x_i + b) + \xi_i \ge 1$,这就是软间隔。多增加的松弛变量,也需要给出代价,所以优化目标变为 $\dfrac{1}{2} \parallel w \parallel^2 + C \sum\limits_{i=1}^{N} \xi_i$ 。这里我们给每一个样本都加上了一个松弛变量。
这样,软间隔最大化的线性支持向量机学习算法转化为凸优化二次问题(原始问题)
s.t:
最小化目标函数 $\eqref{2.1}$ 包含两层含义:使 $\dfrac{1}{2} \parallel w \parallel ^2$ 尽可能小即间隔尽可能大,同时让落在分隔区的特异样本尽可能少(误分类点尽可能少),C 调和两者的系数
通过学习算法即软间隔最大化,可以找到 $(w^{\ast}, b^{\ast})$ ,从而得到分离超平面和分类决策函数。分离超平面和相应的分类决策函数一起,就成为线性支持向量机
2.1 学习算法的对偶算法
原始问题 $\eqref{2.1}, \eqref{2.2}, \eqref{2.3}$ 的对偶问题如下:
s.t.
通过求解上式可以得到解 $\alpha^{\ast} = (\alpha_1^{\ast}, \alpha_2^{\ast}, \dots, \alpha_N^{\ast})^T$,取一个分量 $0 \le \alpha_j^{\ast} \le C$ ,求出 $(w^{\ast}, b^{\ast})$ :
2.2 总结
2.2.1 线性支持向量机学习算法:
输入:训练数据集 $D = {(x_1, y_1), (x_2, y_2), …, (x_N, y_N)}$
输出:分离超平面和分类决策函数
-
选择惩罚参数 C > 0,构造并求解凸二次优化问题: $\eqref{2.4}, \eqref{2.5}, \eqref{2.6}$
求得最优解 $\alpha^{\ast} = (\alpha_1^{\ast}, \alpha_2^{\ast}, \dots, \alpha_N^{\ast})^T$
-
计算 $\eqref{2.7}$
选择 $\alpha^{\ast}$ 的一个分量 $\alpha^{\ast}_j$ 计算 $\eqref{2.8}$
-
求得分离超平面 $w^{\ast} \cdot x + b^{\ast} = 0$
分类决策函数: $f(x) = sign(w^{\ast} \cdot x + b^{\ast})$
2.2.2 支持向量
在线性不可分的情况下,解 $\alpha_{\ast} = (\alpha_1^{\ast}, \alpha_2^{\ast}, \dots, \alpha_N^{\ast})^T$ 中对应于 $\alpha_i^{\ast} \gt 0$ 的样本点 $(x_i, y_i)$ 成为支持向量。
因为 KKT 条件有:
当 $\alpha_i^{\ast} > 0$ 时,括号内式子必须为零,而它们正是支持向量。对于软间隔的支持向量:
-
若 $\alpha^{\ast}_i < C$ ,则 $\zeta_i = 0$ ,支持向量正好在间隔边界上
$\because$ KKT 条件有:$\mu_i^{\ast} \zeta_i^{\ast} = 0$
又约束条件: $C - \alpha_i - \mu_i = 0$
$\therefore$ 当 $\alpha_i < C$ 时,$\mu_i \neq 0 \Rightarrow \zeta_i = 0$
-
若 $\alpha_i^{\ast} = C$
-
$0 < \zeta_i < 1$:分类正确,样本点在间隔边界和分离超平面之间
-
$\zeta_i = 1$:样本点在分离超平面上
-
$\zeta_i > 1$:样本点在分离超平面误分一侧
$\because \alpha_i = C$, $C- \alpha_i - \mu_i = 0$
$\therefore\mu_i = 0$
$\because \mu_i \zeta_i = 0$
$\therefore\zeta_i > 0$ 或者 $\zeta_i = 0$(这里 $\zeta_i = 0$ 不再讨论)
-
3 序列最小最优化算法 SMO
SMO 算法要解如下凸二次规划的对偶问题:
s.t.
这个问题中的变量是拉格朗日乘子,一个变量 $\alpha_i$ 对应一个样本点
SMO 的思想是:如果所有变量的解都满足 KKT 条件,那么最优解就找到了;否则,每次取出两个变量,固定其他变量,求这两个变量的二次规划问题的解。
SMO 算法包括两个部分:一个是求解二次规划问题解析方法,另一个是选择两个变量的启发式方法。
3.1 求解两个变量二次规划问题的解析方法
最优化问题的未剪辑解为:
其中:
经过剪辑后的解
其中:
$y_1 = y_2$:
$y_1 \neq y_2$:
3.2 变量的选择
-
第 1 个变量的选择
遍历所有样本,选择最违背 KKT 条件的样本,选择它对应的参数 $\alpha_i$ 为第一个变量。样本的 KKT 条件与参数的关系:
先检查间隔边界上的样本点,如果它们满足在检查其他样本点
-
第 2 个变量的选择
第 2 个变量的选择希望能使 $\alpha_2$ 有足够大的变化。又因为 $\alpha_2^{new}$ 依赖于 $| E_1 - E_2 |$,所以选择使其最大的 $\alpha_2$
3.3 计算阈值 b 和差值 $E_1$
3.3.1 更新 b 值
完成两个变量的优化之后,要重新计算 b。
当 $0 < \alpha_1^{new} < C$ 时:
同样的,如果 $0 < \alpha_2^{new} < C$,那么:
-
如果 $\alpha_1, \alpha_2$ 同时满足条件[0, C],那么 $b_1^{new} = b_2^{new}$
-
如果 $\alpha_1^{new}, \alpha_2^{new}$ 是 0 或 c,那么选择中点作为 $b^{new}$
3.3.2 更新 $E_1$
其中 $S$ 是所有支持向量 $x_j$ 的集合。
3.4 SMO 算法流程
-
输入:训练数据 $D = \lbrace (x_1, y_1), (x_2, y_2), \dots, (x_N, y_N) \rbrace$
-
输出:近似解 $\hat{\alpha}$
-
过程:
-
取初值 $\alpha^{(0)} = 0$,令 $k = 0$
-
选取优化变量 $a_1^{(k)}, a_2^{(k)}$ ,解析两个变量的最优化问题,得到最优解 $a_1^{(k+1)}, a_2^{(k+2)}$ ,更新 $\alpha = \alpha^{(k+1)}$
-
若在精度 $\sigma$ 范围内满足停机条件则转(4);否则令 $k = k+1$ ,转(2)
-
$\sum\limits_{i=1}^{N} \alpha_i y_i = 0$
-
$0 \le \alpha_i \le C$
-
$y_i \cdot g(x_i) = \begin{cases} \ge 1, & \left\lbrace x_i \mid \alpha_i = 0 \right\rbrace \ = 1, & \left\lbrace x_i \mid 0 < \alpha_i < C \right\rbrace \ \le 1, & \left\lbrace x_i \mid \alpha_i = C \right\rbrace \end{cases}$,其中: $g(x_i) = \sum\limits_{j=1}^{N} a_j y_j K(x_j, x_i) + b$
-
-
取 $\hat{\alpha} = \alpha^{(k+1)}$
-
4 代码实战
4.1 简单 SVM 算法思路
当拿到数据时,我们知道任务是找到一个分离超平面 $(w^\ast, b^\ast)$,把数据分成两个部分,而这个超平面是由参数 $\color{red}{\boldsymbol{\alpha}}$ 决定。简单 SVM 算法的思路是:
-
给每个样本 $(x_k, y_k)$ 设置一个参数 $\alpha_k$
-
选择参数 $\alpha_i, \alpha_j$ 进行优化,具体如下:
-
选择要优化的 $\alpha_i$
选择标准:当此样本的预测误差很大时,则优化
-
$y_i E_i > tol, \alpha_i > 0$
当分类正确时,$\alpha_i$ 会被调整小,那么当这个 $\alpha_i$ 已经在 0 上时,不需要在调整了,因为它的范围是 [0, C]
-
$y_i E_i < - tol, \alpha_i < C$
当分类错误时,$\alpha_i$ 会被调整大,那么当这个 $\alpha_i$ 已经在 C 上时,不需要在调整了,因为它的范围是 [0, C]
其中:
$E_i = g(x_i) - y_i$
$g(x_i) = \sum\limits_{j=1}^{N} a_j y_j K(x_j, x_i) + b$
-
-
随机选择另一个参数 $\alpha_j (\neq \alpha_i)$
-
更新 $\alpha_i, \alpha_j$
-
$\alpha_j^{new, unc} = \alpha_j^{old} + \dfrac{y_j(E_i - E_j)}{\eta}$
-
$\alpha_j^{new} = clip(\alpha_j^{new, unc}, L, H)$
如果 $\mid \alpha_j^{new} - \alpha_j^{old} \mid < \epsilon$ ,重新选择 $\alpha_i, \alpha_j$,否则:
-
$\alpha_i^{new} = \alpha_i^{old} + y_iy_j (\alpha_j^{old} - \alpha_j^{new})$
-
-
-
更新 $b$
当 $0 \lt \alpha_i^{new} < C$ 时:
$b_i^{new} = - E_i - y_i K_{ii} (\alpha_i^{new} - \alpha_i^{old}) - y_j K_{ji} (\alpha_j^{new} - \alpha_j^{old}) + b^{old}$
$b_j^{new} = - E_j - y_i K_{ij} (\alpha_i^{new} - \alpha_i^{old}) - y_j K_{jj} (\alpha_j^{new} - \alpha_j^{old}) + b^{old}$
-
如果 $\alpha_i^{new}, \alpha_j^{new}$ 同时满足条件,则 $b_i^{new} = b_j^{new}$
-
如果 $\alpha_i^{new}, \alpha_j^{new}$ 都是 0 或 C,选择它们的中点作为 $b^{new}$
-
-
更新 $E_i$ 值:
S 是所有支持向量 $x_j$ 的合集
-
迭代设定次数后,完成
4.2 代码实战
import os
import random
import numpy as np
import matplotlib.pyplot as plt
def simple_svm(data, labels, C, epsilon, max_iter):
X = np.array(data)
nsamples = X.shape[0]
y = np.array(labels).reshape(-1, 1)
alpha = np.zeros((nsamples, 1))
b = np.zeros((1,))
iter_num = 0
while iter_num < max_iter:
alpha_pairs_renew = 0
for i in range(nsamples):
gxi = X.dot(X[i]).dot(alpha * y) + b
Ei = gxi - y[i]
if (Ei*y[i] > epsilon and alpha[i] > 0) or (Ei*y[i] < -epsilon and alpha[i] < C):
j = selectJ(i, nsamples)
gxj = X.dot(X[j]).dot(alpha * y) + b
Ej = gxj - y[j]
ai_old = alpha[i].copy()
aj_old = alpha[j].copy()
eta = X[i].dot(X[i]) + X[j].dot(X[j]) - 2 * X[i].dot(X[j])
if eta <= 0: print(">>> eta <= 0"); continue
if y[i] != y[j]:
L = max(0, aj_old - ai_old)
H = min(C, C + aj_old - ai_old)
else:
L = max(0, aj_old + ai_old - C)
H = min(C, aj_old + ai_old)
if L == H: print(">>> L == H"); continue
alpha[j] = aj_old + y[j] * (Ei - Ej) / eta
alpha[j] = clip(alpha[j], L, H)
if (abs(alpha[j] - aj_old) < 0.00001):
#print(">>> alpha[j] 的改变太小");
continue
alpha[i] = ai_old + y[i] * y[j] * (aj_old - alpha[j])
K11 = X[i].dot(X[i])
K12 = X[i].dot(X[j])
K21 = X[j].dot(X[i])
K22 = X[j].dot(X[j])
bi= -Ei - y[i] * K11 * (alpha[i] - ai_old) - y[j] * K21 * (alpha[j] - aj_old) + b
bj= -Ej - y[j] * K12 * (alpha[i] - ai_old) - y[j] * K22 * (alpha[j] - aj_old) + b
if 0 < alpha[i] < C: b = bi
elif 0 < alpha[j] < C: b = bj
else: b = (bi + bj) / 2.0
alpha_pairs_renew += 1
print("第[{}]次迭代,第[{}]样本,第[{}]次更新".format(iter_num, i, alpha_pairs_renew))
if alpha_pairs_renew == 0:
iter_num += 1
else:
iter_num = 0
return alpha, b
def clip(num, L, H):
if num > H:
num = H
elif num < L:
num = L
return num
def selectJ(idx, num):
j = idx
while j == idx:
j = random.randint(0, num-1)
return j
def load_dataset(filename):
X = []
y = []
curdir = os.path.relpath('.')
filepath = os.path.join(curdir, filename)
with open(filepath) as fr:
for line in fr.readlines():
data = line.strip().split('\t')
X.append([float(data[0]), float(data[1])])
y.append([float(data[-1])])
return np.array(X), np.array(y)
def get_w(data, labels, alpha):
return np.sum(data*(alpha * labels), axis=0)
def show_classifier(data, labels, w, b):
X_plus = []
X_minus = []
for i, x in enumerate(data):
if labels[i] > 0:
X_plus.append(x)
else:
X_minus.append(x)
x_plus_np = np.array(X_plus)
x_minus_np = np.array(X_minus)
plt.scatter(x_plus_np[:, 0].transpose(), x_plus_np[:, 1].transpose(), s=30, alpha=0.8)
plt.scatter(x_minus_np[:, 0].transpose(), x_minus_np[:, 1].transpose(), s=30, alpha=0.8)
x1 = np.max(data, axis=0)[0]
x2 = np.min(data, axis=0)[0]
a1, a2 = w
a1 = float(a1)
a2 = float(a2)
y1, y2 = (-b - a1*x1) / a2, (-b - a1*x2) / a2
plt.plot([x1, x2], [y1, y2])
for i, a in enumerate(alpha):
if(abs(a) > 0.001):
x, y = data[i]
plt.scatter([x], [y], s=150, c='none', alpha=0.8, linewidths=1.5, edgecolors='red')
plt.show()
if __name__ == '__main__':
data, labels = load_dataset('svm_dataset.txt')
alpha, b = simple_svm(data, labels, 0.6, 0.001, 40)
w = get_w(data, labels, alpha)
show_classifier(data, labels, w, b)
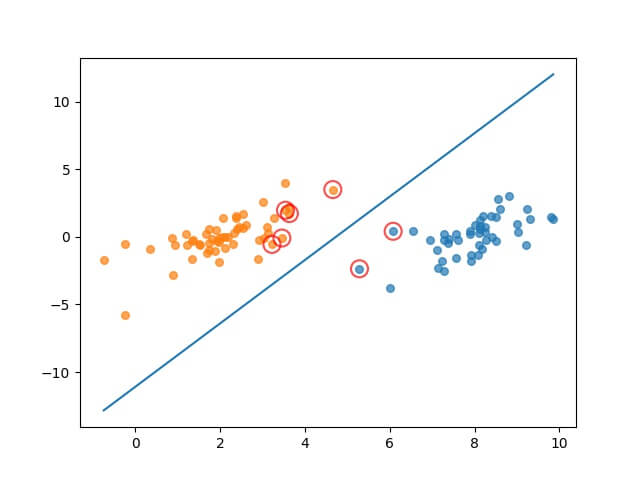
4.3 执行结果
4.4 优化的 SMO 算法
-
当迭代次数超过最大值,并且遍历整个集合都没有对任意 $\alpha$ 进行修改时,退出循环
-
如果是全新数据集:
循序选择 $\alpha_i$,再优化 $\alpha_i, \alpha_j$
-
否则:
找到 $0 \lt \alpha_i \lt C$ 的 $\alpha_i$ ,再优化 $\alpha_i, \alpha_j$
-
4.5 实战代码
import os
import random
import numpy as np
import matplotlib.pyplot as plt
def load_dataset(filename):
X = []
y = []
curdir = os.path.relpath('.')
filepath = os.path.join(curdir, filename)
with open(filepath) as fr:
for line in fr.readlines():
data = line.strip().split('\t')
X.append([float(data[0]), float(data[1])])
y.append([float(data[-1])])
return np.array(X), np.array(y)
def clip(num, L, H):
if num > H:
num = H
elif num < L:
num = L
return num
def selectJrand(idx, num):
j = idx
while j == idx:
j = random.randint(0, num-1)
return j
def get_w(data, labels, alpha):
return np.sum(data*(alpha * labels), axis=0)
class opt_struct:
def __init__(self, data, labels, c, toler):
self.X = data
self.labels = labels
self.c = c
self.tol = toler
self.m = np.shape(data)[0]
self.a = np.zeros((self.m, 1))
self.b = 0
self.e_cache = np.zeros((self.m, 2))
def update_ek(self, os, k):
ek = os.calc_ek(os, k)
os.e_cache[k] = [1, ek]
def calc_ek(self, os, k):
'''
fxk = sum_i(ai * yi * K(X, X[k])) + b
'''
fxk = os.X.dot(os.X[k]).dot(os.a * os.labels) + os.b
ek = fxk - float(os.labels[k])
return ek
def selectJ(self, i, os, ei):
'''
1. 找到 e_cache 中的非零项
2. 如果非零项没有,随机选择一个 j,计算 ej
3. 否则,对于每一个非零项k
3.1 k != i
3.2 计算误差 ek = calc_ek(os, k)
3.2 计算与ei相差最大的ek
4. 返回对应的 k 和 ek
'''
max_k = -1
max_delta_e = 0
ej = 0
os.e_cache[i] = [i, ei]
vaild_ecache_list = np.nonzero(os.e_cache[:, 0])[0]
if (len(vaild_ecache_list) > 1):
for k in vaild_ecache_list:
if k == i: continue
ek = os.calc_ek(os, k)
delta_e = abs(ei - ek)
if (delta_e > max_delta_e):
max_k = k
max_delta_e = delta_e
ej = ek
return max_k, ej
else:
j = selectJrand(i, os.m)
ej = os.calc_ek(os, j)
return j, ej
def innerL(i, os):
'''
1. 计算样本 i 的误差
2. 如果误差足够大,而且不在边界上:
2.1 选择 aj
2.2 根据 ai ?= aj,计算 L, H
2.3 计算 eta (< 0)
2.4 计算 aj = aj - yj*(ei - ej)/eta, aj = clip(aj, L, H)
2.5 把 aj 更新至 e_cache
2.6 计算 ai = ai + yj*yi*(aj_old - aj)
2.7 把 ai 更新至 e_cache
2.8 计算
b1 = -b - ei - yi(ai - ai_old) * k11 - yj(aj - aj_old) * k12
b2 = -b - ej - yi(ai - ai_old) * k12 - yj(aj - aj_old) * k12
如果 0 < ai < C:b = b1
如果 0 < aj < C:b = b2
否则: b = (b1 + b2) / 2
3. 否则:
返回 0
'''
ei = os.calc_ek(os, i)
if (os.labels[i]*ei < -os.tol and os.a[i] < os.c) or \
(os.labels[i]*ei > os.tol and os.a[i] > 0):
j, ej = os.selectJ(i, os, ei)
ai_old = os.a[i].copy()
aj_old = os.a[j].copy()
if (os.labels[i] != os.labels[j]):
L = max(0, os.a[j] - os.a[i])
H = min(os.c, os.c + os.a[j] - os.a[i])
else:
L = max(0, os.a[j] + os.a[i] - os.c)
H = min(os.c, os.a[j] + os.a[i])
if L == H: print("L == H");return 0
eta = 2.0 * os.X[i, :].dot(os.X[j, :]) - os.X[i, :].dot(os.X[i, :]) - \
os.X[j, :].dot(os.X[j, :])
if eta >= 0: print("Eta >= 0"); return 0
os.a[j] -= os.labels[j] * (ei - ej) / eta
os.a[j] = clip(os.a[j], L, H)
os.update_ek(os, j)
if abs(os.a[j] - aj_old) < 0.00001:
print("aj 变化太小")
return 0
os.a[i] += os.labels[i] * os.labels[j] * (aj_old - os.a[j])
os.update_ek(os, i)
k11 = os.X[i, :].dot(os.X[i, :])
k12 = os.X[i, :].dot(os.X[j, :])
k21 = os.X[j, :].dot(os.X[i, :])
k22 = os.X[j, :].dot(os.X[j, :])
b1 = os.b - ei - os.labels[i] * (os.a[i] - ai_old) * k11 - \
os.labels[j] * (os.a[j] - aj_old) * k21
b2 = os.b - ej - os.labels[i] * (os.a[i] - ai_old) * k12 - \
os.labels[j] * (os.labels[j] - aj_old) * k22
if 0 < os.a[i] < os.c: os.b = b1
elif 0 < os.a[j] < os.c: os.b = b2
else: os.b = (b1 + b2) / 2
return 1
else:
return 0
def show_classifier(data, labels, w, b):
X_plus = []
X_minus = []
for i, x in enumerate(data):
if labels[i] > 0:
X_plus.append(x)
else:
X_minus.append(x)
x_plus_np = np.array(X_plus)
x_minus_np = np.array(X_minus)
plt.scatter(x_plus_np[:, 0].transpose(), x_plus_np[:, 1].transpose(), s=30, alpha=0.8)
plt.scatter(x_minus_np[:, 0].transpose(), x_minus_np[:, 1].transpose(), s=30, alpha=0.8)
x1 = np.max(data, axis=0)[0]
x2 = np.min(data, axis=0)[0]
a1, a2 = w
a1 = float(a1)
a2 = float(a2)
y1, y2 = (-b - a1*x1) / a2, (-b - a1*x2) / a2
plt.plot([x1, x2], [y1, y2])
for i, a in enumerate(alpha):
if(abs(a) > 0.001):
x, y = data[i]
plt.scatter([x], [y], s=150, c='none', alpha=0.8, linewidths=1.5, edgecolors='red')
plt.show()
def opt_smo(data, labels, C, toler, max_iter, ktup=('lin', 0)):
'''
1. 当迭代次数 < 最大值,并且(有优化的 a 或者是新集合)
1.1 如果是新集合:
抽取集合中的每一个样本
优化 ai, aj
1.2 否则:
找出 a 的非边界集合
对于非边界集合中的每一个 a:
优化 ai, aj
2. 返回 a, b 值
'''
os = opt_struct(data, labels, C, toler)
iter = 0
entire_set = True
achanged = 0
while iter < max_iter and (achanged > 0 or entire_set):
achanged = 0
if entire_set:
for i in range(os.m):
achanged += innerL(i, os)
print("全集,迭代:%d i:%d 成对修改:%d" % (iter, i, achanged))
iter += 1
else:
non_bound_is = np.nonzero((os.a > 0) * (os.a < C))[0]
for i in non_bound_is:
achanged += innerL(i, os)
print("non-bound, iter: %d, i:%d, 成对修改:%d" % \
(iter, i, achanged))
iter += 1
if entire_set: entire_set = False
elif achanged == 0: entire_set = True
print("iter number:", iter)
return os.a, os.b
if __name__ == '__main__':
data, labels = load_dataset('svm_dataset.txt')
alpha, b = opt_smo(data, labels, 0.6, 0.001, 40)
w = get_w(data, labels, alpha)
show_classifier(data, labels, w, b)
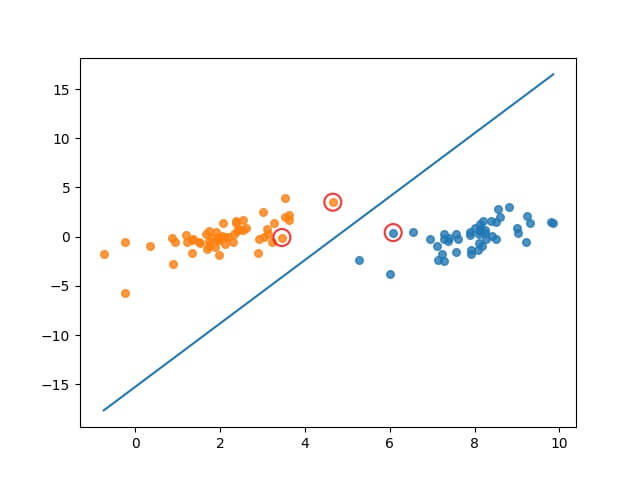
4.6 执行结果